Friday, 21 September 2007
DOAJ - Directory of Open Access Journals
Stumbled across DOAJ, which has some useful biodiversity-related content. Could think about adding this to my OpenURL resolver...Posted by Rod Page at Friday, September 21, 2007 2 comments Links to this post

Thursday, 6 September 2007
JSTOR
JSTOR is a major user of SICIs, hence I've been exploring it to see how hard it would be to add support for JSTOR (and SICIs) to my OpenURL resolver. Helpfully JSTOR provides a list of journals they archive, which is also available as a comma delimited file. I grabbed the biological serials collection list and extracted information on the journals JSTOR carries.

Another incidental by product was a further 87 new journals to my database of journal names and ISSNs. Just to remind myself how to do this, this is the SQL to insert the new journal names and ISSNs.
INSERT INTO issn(title, issn)
SELECT jstor.journal, jstor.issn FROM jstor
LEFT JOIN issn ON jstor.journal = issn.title
WHERE issn.title IS NULL;
The next step would be to add code to the OpenURL resolver so it could figure out whether a reference was in JSTOR and provide a link to that resource (as well as any other links I have). For example, Walker et al. "The Effect of Feeding History on Retreat Construction in the Wolf Spider Hogna helluo (Araneae, Lycosidae)" is in JSTOR (sici:0161-8202(1999)27<689>2.0.CO;2-7), and is also in my database as the PDF is freely available online.
It would be nice if my OpenURL resolver could take a SICI and return metadata that included both the availability in JSTOR and on the American Arachnological Society web site.Posted by Rod Page at Thursday, September 06, 2007 0 comments Links to this post
Thursday, 30 August 2007
Piggy Bank and bioGUID - browsing the biodiversity Semantic Web
Piggy Bank is, according to its developers:
...a Firefox extension that turns your browser into a mashup platform, by allowing you to extract data from different web sites and mix them together.
I've been rather underwhelmed in the past, but Jim Balhoff asked me why bioGUID didn't play ball, so I decided to take another look.
On pointing Piggy Bank at a bioGUID page, such as casent0498428 and clicking on the "data coin" icon in the bottom right corner of the Firefox browser window failed to produce anything interesting (Piggy Bank just grabbed some text from the web page, not the underlying RDF). After a bit of fussing, I finally got bioGUID to work with Piggy Bank.
BioGUID resolves a GUID and returns RDF as an XML document, with a XSL instruction included so that the web browser renders it as HTML. This means that a user with a web browser gets a nicley formatted page, but a Semantic Web tool gets RDF. However, Piggy Bank needs some help. First, I include a link to the RDF in the <head> element of the HTML, as described on the Piggy Bank web sitee.g.:
<link rel="alternate" type="application/rdf+xml"
href="http://bioguid.info/rdf/casent:0008682-d03&format=raw">
The &format=raw parameter is important as this tells bioGUID to return RDF with the MIME type "application/rdf+xml". Piggy Bank needs this MIME type set, otherwise it just parses HTML. I normally return RDF as "application/xml" so it displays nicely in web browsers if I'm debugging, and to ensure the XML is transformed into HTML. Clearly I'm going to have to rethink this, perhaps by exploring content negotiation.
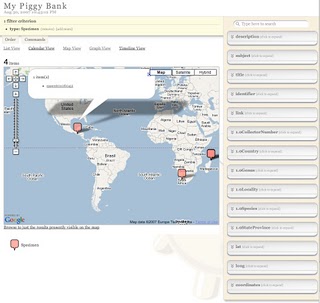
Anyway, for the time being Piggy Bank and bioGUID seem to work together, as this screen shot shows:
If you want to explore Piggy Bank as a Semantic WEb browser for biodoversity data, one place to start is http://bioguid.info/pmid:17079492 and the sequences it links to, many of which link to specimens.Posted by Rod Page at Thursday, August 30, 2007 0 comments Links to this post
Wednesday, 15 August 2007
OpenURL and COinS
I've improved the bioGUID OpenURL service, based on my experience with the OpenURL Referrer extension for FireFox. This extension takes COinS links in HTML and inserts a link to an OpenURL resolver. The EDIT scratchpads being developed by Vince Smith and colleagues at the Natural History Museum contain COinS (see the APOL - Abyssal Polychaetes OnLine bibliography, for an example). I installed the OpenURL Referrer extension, but my OpenURL resolver broke. Turned out the the COinS want OpenURL 1.0, whereas I supported the much simpler version 0.1 (Caveat Lector pretty much sums up how I feel about this). Anyway, a quick hack of my code and it now works.
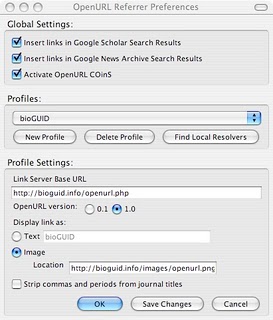
If you add http://bioguid.info/openurl.php as a profile, you can then use my OpenURL resolver (there's even a little button to click on at http://bioguid.info/images/openurl.png). Once installed, scratchpads such as APOL - Abyssal Polychaetes OnLine bibliography now have links to the OpenURL resolver.
Why use bioGUID's service? Well, in addition to supporting papers that have DOIs, I'm adding other sources, as mentioned earlier in this blog, and on iPhylo. Some 9000 freely available full text articles are now available through this service. There's still a lot more to do to this service, such as supporting other identifiers (e.g., PubMed and SICIs).
Thanks to Julius Welby for reminding me about COinS.Posted by Rod Page at Wednesday, August 15, 2007 2 comments Links to this post Labels: COinS, OpenURL, scratchpads
Wednesday, 6 June 2007
Banff Manifesto
From Bio2RDF, I stumbled across this link to the Banff Manifesto. To quote:
Some participant from the HCLS-DI2007 workshop, and from the I3 Workshop propose to the community of life science to establish an authority for attributing namespaces used in semantic web to build URIs. This authority will also establish a set of rules for the construction of well formed RDF documents. When someone will use URI approved from the BM authority, they will know that some standard of naming are upheld. The set of rules are good pratices that need to be followed to be in recognized by the BM community.
Much in the way DOI work, BM will certified the appartenance of a namespace to a data provider and disambiguate the naming for it.
Essentially, it proposes that identifiers are written as
authority_namespace:public_namespace:private_identifier
where the authority_namespace is bm.Resolution (at least in the examples presented) is via a persistent URL, e.g. bm:uniprot:p26838 becomes http://purl.org/bm/uniprot:p26838.
This looks to be much the same idea as bioGUID. Interestingly, one of the exmaples of the URI chaos at present is a DOI for a Protein Data Bank record (doi:10.2210/pdb2b3y/pdb. This DOI resolves to a compressed file served by FTP. You can see the web version here. The CrossRef XML for this DOI is interesting, in that sort-of treats the record as an article, but also has a component-list (which curiously states that this record is a part of itself).Posted by Rod Page at Wednesday, June 06, 2007 0 comments Links to this post
Tuesday, 29 May 2007
OpenURL resolver for Psyche
Following on from first efforts with Journal of Arachnology described on iPhylo, I've added Psyche to my OpenURL resolver. Psyche is the journal of the Cambridge Entomological Club. What makes it easy to add is that there are full text PDFs available for most articles, Jonathan Rees has created a series of XML files for each issue (e.g., 103.xml), listing metadata for each article, and the URLs for the PDFs are easy to construct from the metadata. So, it was simply a case of harvesting the XML files, extracting the metadata, and adding this to a local MySQL database.
There were some minor "gotchas", such as the presence of entities in the XML (e.g. é for the character é). These weren't declared, so I needed to stick these into each XML file:
<!ENTITY aelig "æ" >
<!ENTITY ldquo "“">
<!ENTITY rdquo "”">
<!ENTITY lsquo "“">
<!ENTITY rsquo "”">
<!ENTITY ouml "ö">
<!ENTITY uuml "ü">
<!ENTITY mdash "—">
<!ENTITY eacute "é">
<!ENTITY euml "ë">
<!ENTITY oelig "œ">
<!ENTITY OElig "Œ">
<!ENTITY AElig "Æ">
<!ENTITY acir "â">
<!ENTITY oacute "ó">
<!ENTITY iacute "í">
<!ENTITY aacute "á">
<!ENTITY ndash "–">
<!ENTITY atilde "ã">
<!ENTITY uacute "ú">
<!ENTITY auml "ä">
<!ENTITY ocirc "ô">
Now, my OpenURL resolver will check if you are trying to resolve a link to an article in Pysche, and if it knows where the PDF is you will be taken there. For example, this link http://bioguid.info/openurl.php?sid=paracite&aulast;=Gardner&aufirst;=B&atitle;=Observations on three species of Phidippus jumping spiders (Araneae: Salticidae)&title;=Psyche, Camb.&date;=1965&year;=1965&volume;=72&spage;=133&epage;=147 goes to the PDF of this paper on Phidippus.Posted by Rod Page at Tuesday, May 29, 2007 0 comments Links to this post Labels: entity, OpenURL, Psyche, XML
Monday, 23 April 2007
Blank nodes for specimens without URI
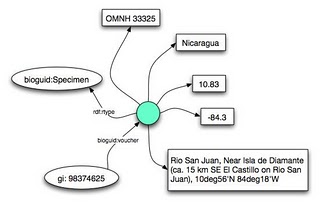
Some specimens in GenBank can be easily linked to an external record via a URI (albeit one I've constructed), but for many GenBank sequences the specimen is either so poorly described, or doesn't have a digital representation, that simply linking to a URI is not possible. After playing with generating my own URIs for records in a local MySQL database of specimens, it occurred to be (eventually) that blank nodes might be a useful way to handle these. That is, a node in the RDF that has no URI, but to which all the information about that specimen is linked. The diagram on the right shows the model. In RDF/XML, it would look something like this:
<bioguid:voucher rdf:parseType="Resource">
<rdf:type rdf:resource="http://bioguid.info/schema/0.1/Specimen"/>
<darwin:Country>Nicaragua</darwin:Country>
<darwin:Locality>Rio San Juan, 10deg56'N 84deg18'W</darwin:Locality>
<geo:lat>10.93</geo:lat>
<geo:long>-84.3</geo:long>
<dc:title>OMNH 33325</dc:title>
</bioguid:voucher>
The original GenBank record is DQ502492.
In the absence of a URI, we make statements such as "the specimen with the title 'OMNH 33325'".Posted by Rod Page at Monday, April 23, 2007 0 comments Links to this post Labels: blank node, RDF, specimen, voucher